On this page
GTM teams are starting to run several AI agents at once instead of a single tool: agents that score leads, draft outreach, watch pipeline, and keep attribution current, all working off a shared record rather than handing work down a chain. Before any of them can do its job well, something has to keep the truth about each account current. That is this agent's job, and it's the reason it runs first. Get this layer wrong and every agent after it inherits the mistake.
A research and enrichment agent does one job well: it keeps what you know about an account true. It watches signals across the open web, intent networks, your CRM, and product usage, notices when something about the account has changed, and updates the record without anyone asking it to. That last part is the whole point. ZoomInfo and Clearbit hand you a snapshot. Clay runs when you configure it to run. A research agent keeps watching.
You probably already run something in this category. Clay, ZoomInfo, Clearbit, one of them is usually wired in somewhere. So the question isn't whether you need account intelligence. You do. It's whether what you're running keeps pace with how your pipeline actually moves.
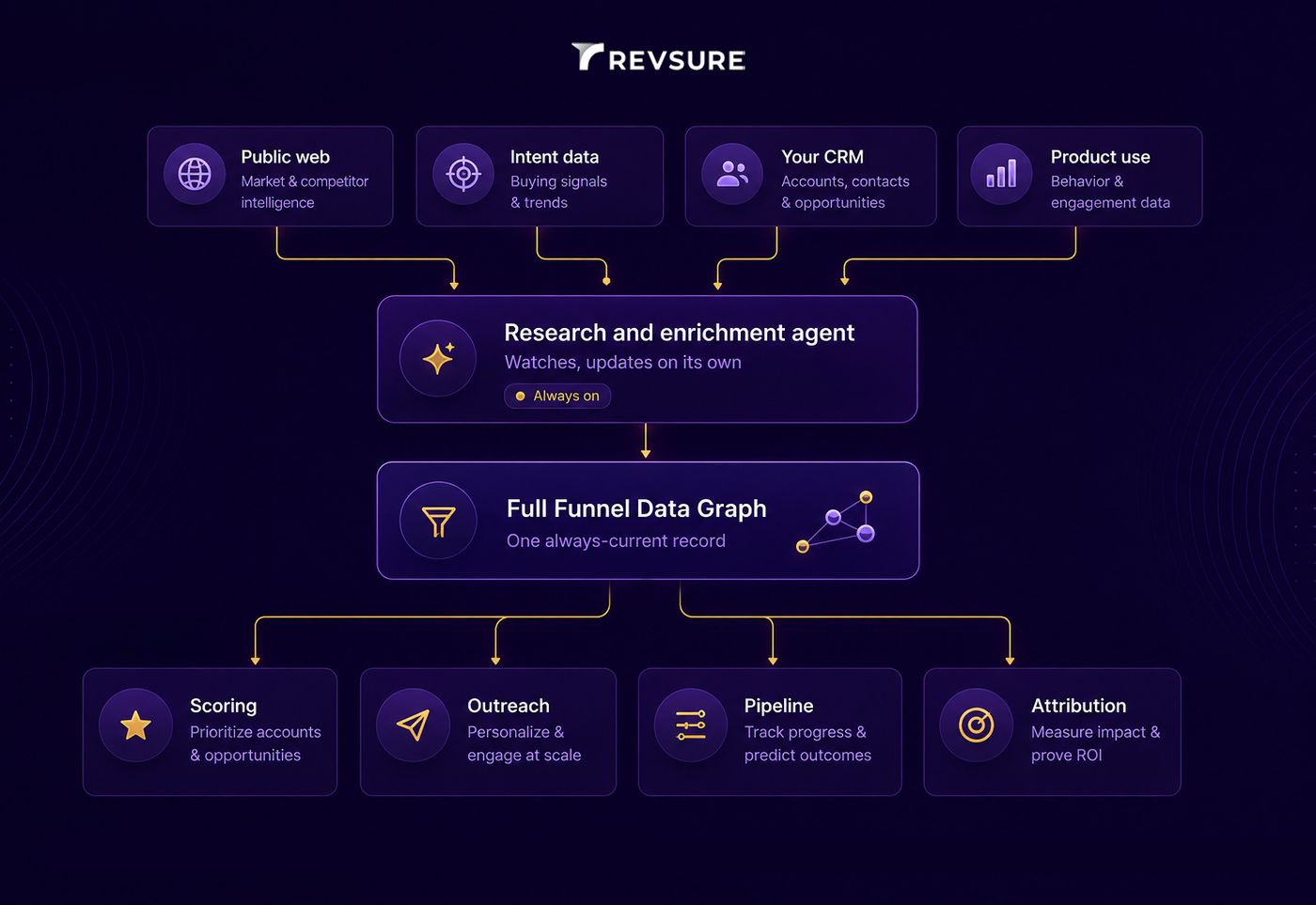
Many signals in, one continuously updated account record, every downstream agent reading from it
Why your account data goes stale
It goes stale because buyers don't move on your enrichment schedule. An account shows interest, goes quiet, brings in a new stakeholder, switches what it's evaluating, and none of that shows up in a record last touched the day the account entered your pipeline.
Reps work from that record anyway. They call into accounts that have already changed shape, miss the new decision-maker, and open with a pitch that's a quarter out of date. The cost shows up as bounced emails, wasted research hours, and winnable deals lost because nobody knew the account had moved.
So why can't the tools you already own close that gap? It comes down to what they were built to do.
Why your current tools can't fix it
ZoomInfo and Clearbit sell you a clean view of an account at a moment in time, and that view is useful right up until the account changes. Clay goes further, letting you build enrichment workflows that pull from many sources, and teams who've invested in it have gotten real mileage. But all of them act only when a person tells them to. None of them watch an account and decide, on their own, that the record needs to change.
A research agent does. It runs in the background, reads across sources, works out what's actually different about the account now, and writes that back so the rest of your system can use it. RevSure's Account Research Agent does this in minutes: it pulls together company details, tech stack, and decision-makers, then maps how the account has engaged across marketing, sales, and product.
To see why that's different in kind, not just degree, it helps to look at what the agent is actually watching.
What a research agent keeps track of
Company facts. The basic structure of a company, sometimes called firmographics: headcount, funding stage, who they're hiring. A company that was 200 people when it entered your pipeline and is now 400 with an open VP of Sales role is a different account than its record says. Static enrichment doesn't know that unless someone re-runs it.
Their tech stack. What software they run, the technographic picture. A new data warehouse, or a competitor's product going live in their stack, is a reason to change how the conversation starts.
What they're paying attention to. The content an account is reading and the categories it's researching, which hint at where it sits in an evaluation.
Who's involved. Not the one contact with the most complete LinkedIn profile, which is where point tools usually stop, but a living map of the buying group: who matters, what their role suggests about their stake, and how recently each person has been engaged.
None of that is worth much if the agent reads from a thin slice of the picture, so the range of sources matters as much as the watching.
Where the signals come from
The agent reads widely. Public signals like job posts, press, and executive statements. Third-party intent data from networks like Bombora, G2, and TechTarget. Your own first-party behavior, the website visits and campaign engagement already sitting in your CRM and marketing tools. And your internal records: deal history and product usage on active trials. That last category is usually the richest signal you have, and the one outside tools can't touch, because it's yours.
Reading widely creates its own problem: the same company can show up as three different records across three systems. So before the agent does anything else, it resolves all of those signals to a single account identity through identity resolution, so everything downstream is reasoning about one account, not three fragments of it.
Once the agent has read and resolved all of that, the question becomes what it does with it.
What it produces, and where that goes
What the agent produces is a single account record that stays current: today's company facts, an up-to-date map of who's involved, what they run, and a full engagement history. On top of that, it flags the moments that matter. A new C-suite hire. A funding round. A software change that looks like an active evaluation. A spike in research activity.
Here's the part that separates an agent from a better enrichment tool. When it updates an account, it doesn't just edit a field in one system. It writes the change into RevSure's Full Funnel Data Graph, the shared record of every account that the rest of the platform reads from. The moment the research agent learns something, the scoring agent re-ranks the account, the pipeline agent adjusts what it's watching, and the agent drafting outreach updates its message. Nobody has to carry the insight from one place to another.
Why this is the foundation agent
That last point is what makes the research agent the foundation rather than another enrichment tool. Every agent downstream is only as good as the account it reasons about, and they all read from the record this one keeps.
When the real-time lead scoring agent re-ranks an account, it's re-ranking off this agent's read. When the AI SDR agent drafts outreach, it's personalizing off this agent's read. An outreach agent personalizing off a stale record isn't personalizing. It's guessing politely. That dependency is exactly why fixing the research layer first changes everything after it.
What it changes for RevOps and SDR teams
For RevOps, this shifts what "good data" means. The question stops being "is the CRM enriched" and becomes "how long does it take us to notice an account has changed, and act on it." That's a speed question, not a hygiene one.
For SDR managers, the change is more direct. Reps stop burning the front of their day on pre-call research, because the account in front of them already reflects the latest read: the buying group updated, recent triggers flagged, engagement current. By some estimates, that recovers three to six hours per rep per week. The work shifts from building lists to reading signals and deciding what to do about them.
A demand generation leader at an enterprise AI search company put the effect plainly: with the data work carried for them, it was "like having a data engineer at your disposal all the time." That is the shift in a sentence. Research stops being something a person does before each call and becomes something the system keeps current in the background.
That shift only holds, though, if what you've bought is a real agent and not enrichment with a new label. There's a fast way to check.
How to tell a real agent from a rebrand
When a vendor tells you they have a research agent, there's a quicker check than asking what sources it pulls from. Everyone has a long list there. Ask instead: when the agent spots a change on an account, what happens next, and how fast?
If the answer involves a nightly sync, a separate workflow, or a person reviewing the output before anything moves, it's an enrichment tool with an agent label. A real one propagates the change to every other agent automatically, with no review step between noticing and acting. If you want to see what that looks like without engineering involvement, RevSure's Agent Builder deploys and configures research agents directly.
Where to go next
This post is one piece of a larger system. For how all of these agents work together, start with the pillar: Multi-Agent AI Architectures for Revenue Operations. For the agents that read from this one, see real-time lead scoring and the AI SDR agent. And for the bigger decision of whether to build this capability in-house or activate it, see Build or Activate: The Real Math on Time, Cost, and Risk.
Frequently asked questions
What is a research and enrichment agent?
It's the first agent in a multi-agent GTM system. It watches an account's signals continuously, across public data, intent networks, your first-party behavior, and your CRM, and keeps the account record current on its own. Unlike static enrichment, it doesn't populate a record once and stop. It writes updates into a shared record that every other agent reads from. In RevSure, the Account Research Agent plays this role and feeds the Full Funnel Data Graph.
How is it different from ZoomInfo or Clay?
ZoomInfo and Clearbit give you a snapshot at a point in time. Clay lets you build enrichment workflows that you configure and trigger. Both are useful. Neither watches an account continuously and updates other systems without you starting the process. A research agent does all of that on its own, which is the difference between data you refresh and data that refreshes itself.
What data does it use?
Four sources: public signals (job posts, press, executive statements, LinkedIn activity), third-party intent networks (Bombora, G2, TechTarget), your first-party behavior already stored in your CRM and marketing tools, and your internal records like deal history and product usage. It resolves all of them to one account identity so the same company doesn't show up as three different records.
Does it replace my current enrichment tools?
Not necessarily. Many research agents sit on top of sources like ZoomInfo and Clearbit and pull from them as part of a wider read. The difference isn't the data sources. It's that the agent runs continuously and makes every update immediately available to the rest of the system.
How does it help SDR productivity?
Mostly by giving reps their time back. Instead of researching an account before every call, they open one that already reflects the latest signals, so their hours go to conversations rather than lookups. Reps working from current, trigger-informed context also tend to convert better than reps working from stale records, regardless of how much they send.
What should RevOps look for when evaluating one?
Two questions cut through most vendor positioning. First, does it update the account continuously, or on a batch schedule? Batch is enrichment; continuous is agent behavior. Second, when it flags a change, what happens next, and how fast? If a human has to act on the output before anything else moves, the coordination isn't real. A genuine agent passes its findings to every other agent automatically.